
















Nella Parte 1 di questo post del blog, abbiamo introdotto le distribuzioni di probabilità di vendita censurate. Sporchiamoci ora le mani e vediamo cosa significa in pratica la capacità finita. Iniziamo sottolineando le insidie sottili in cui si potrebbe inavvertitamente cadere per poi condividere il modo in cui in genere risolviamo la situazione.
Confondere le vendite con la domanda
Il tuo manager potrebbe chiederti di ignorare completamente questo post sul blog per ottenere sia un "primo modello semplice" che una "stima approssimativa della qualità del modello". Potresti fare un respiro profondo e farlo, cioè interpretare direttamente i numeri di vendita come vera domanda.
Cosa potrebbe mai succedere? Un confronto ingenuo tra una domanda prevista imparziale e le vendite osservate produrrà tipicamente il verdetto "la previsione è distorta, è una previsione eccessiva": la capacità finita ha spinto verso il basso il valore delle vendite osservate. Più spesso si raggiunge la capacità, più le vendite ne risentono. In pratica, ciò che è particolarmente dannoso è che l'impatto della capacità limitata varierà considerevolmente tra i gruppi di prodotti: i prodotti freschi devono esaurire le scorte di tanto in tanto per evitare sprechi e la capacità viene colpita di tanto in tanto. I prodotti non deperibili vengono spesso riforniti in modo mai esaurito e la capacità non viene quasi mai raggiunta. Un confronto tra gruppi di prodotti risentirà enormemente del diverso impatto delle diverse strategie di capacità/scorte.
Ma in primo luogo, otterremmo un modello imparziale? Questo è improbabile: durante l'addestramento, il modello apprende direttamente una domanda distorta. Di una distribuzione completa della domanda con una media di 9,7, il modello imparerebbe solo quella vincolata e censurata, che viene fornita con un valore medio inferiore, come si può vedere nella figura seguente:

Il circolo vizioso di una previsione sottostimata che porta a un ordine basso, a più rotture di stock, a una previsione ancora più sottostimata è impostato in un movimento in continua accelerazione – mentre la valutazione conferma che "va tutto bene" e che "la previsione di vendita va bene". In altre situazioni, i limiti di capacità durante la fase di formazione e valutazione potrebbero variare per qualsiasi motivo, con conseguenze perniciose sull'interpretazione del bias osservato (o sulla sua mancanza).
Se hai letto fino a qui, probabilmente capisci che le vendite e la domanda non si equivalgono, e sarai in grado di discutere in modo convincente con il tuo manager per prendere la strada più lunga e precisa.
Selezione dei giorni in cui la domanda non è stata soddisfatta
L'insidia di cui sopra è abbastanza intuitiva: la domanda e le vendite sono quantità diverse, e impostarle uguali quando non lo sono è chiaramente problematico. La seconda insidia che voglio che tu eviti è un po' più sottile (prenota un incontro di due ore per spiegarlo al tuo manager): un'idea che tipicamente si fa avanti nei progetti è quella di addestrare o valutare i modelli solo sugli eventi di no-capacity-hit, cioè in quei giorni in cui le vendite non hanno saturato la capacità. Cioè, tutti gli eventi per i quali è avvenuta la censura (le vendite sono uguali alle scorte) vengono rimossi dalla formazione o dalla valutazione, e vengono mantenuti solo i valori di vendita inferiori alla capacità. Gli eventi rimanenti sono eventi non vincolati, il che, questa è la speranza, renderebbe la formazione e la valutazione imparziali.
Tuttavia, non è affatto così! Selezionando i giorni in cui la capacità non è stata raggiunta, si selezionano naturalmente quegli eventi di fluttuazione negativa per i quali la domanda è avvenuta per caso come particolarmente piccola. Cioè, si sta introducendo un bias di selezione concentrandosi su quegli eventi che sono valori anomali negativi. Un tale set di dati di formazione o valutazione non riflette la domanda reale in modo imparziale, ma ne produce una negativa. Gli eventi per i quali la capacità è stata colpita sono quelli per i quali la domanda reale è stata, a causa del caso, un po' più grande della media. Questi eventi sarebbero necessari per registrare un valore complessivo non distorto. Nella figura seguente, vediamo perché la rimozione degli eventi di superamento della capacità può essere ancora peggiore rispetto al training sull'intero set di dati di valori di vendita (ovvero sulla domanda limitata): Le vendite medie condizionate al mancato raggiungimento della capacità (linea tratteggiata verde) sono inferiori alle vendite medie complessive (linea rossa), perché le vendite medie al di sotto del raggiungimento della capacità (linea nera) contribuiscono a valori più elevati. Ricorda: ciò su cui vorremmo imparare o ciò che abbiamo previsto è la domanda media con il punto blu.
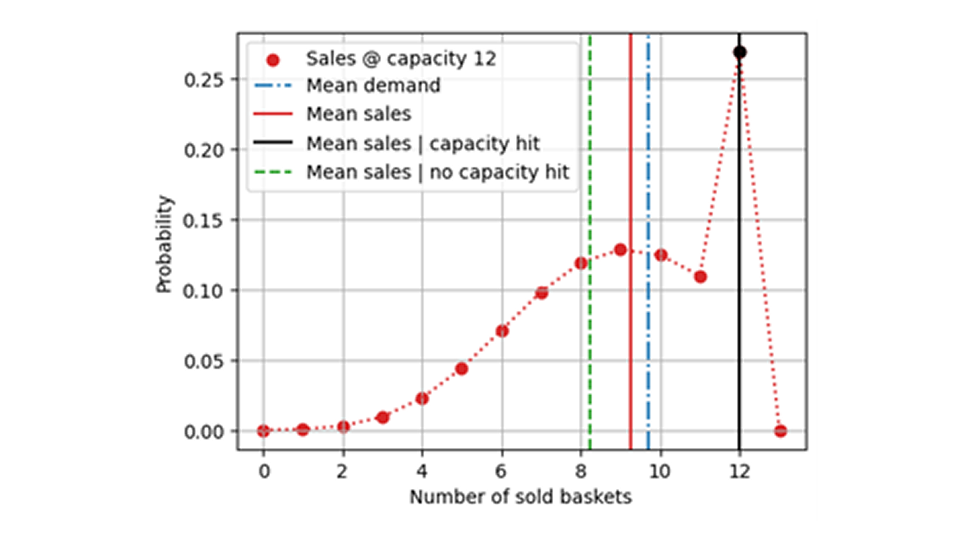
Statisticamente parlando, i giorni in cui non si è esauriti non sono rappresentativi per tutti i giorni, ma sono quelli in cui meno persone sono entrate al supermercato. Forse le fragole non erano fresche o una campagna promozionale per i mango ha fatto sì che le persone se ne andassero: in ogni caso, selezioneremmo valori anomali e non possiamo aspettarci che siano imparziali!
Nel caso in cui si voglia optare per la strategia inversa e selezionare quegli eventi per i quali la capacità è stata raggiunta, si sta distorcendo il set di dati ancora più fortemente: le vendite medie non hanno quindi nulla a che fare con la previsione, poiché riproducono esattamente la strategia di impostazione della capacità – le vendite quindi corrispondono banalmente alla capacità sempre.
Separare i dati di valutazione in base a "la capacità è stata raggiunta" rispetto a "la capacità non è stata raggiunta" viola anche un importante principio della valutazione delle previsioni: non suddividere mai i dati in base a un criterio sconosciuto al momento della previsione. Tale suddivisione induce quasi sempre un sottile bias di selezione nei gruppi risultanti. Un effetto simile è discusso nel post del blog You should not always know better.
Come evitare le insidie
Per quanto riguarda l'addestramento, la conclusione è terribile: non c'è modo di evitare l'addestramento "corretto" utilizzando metodi come la regressione di Tobit, che tiene conto del fatto che osservare 12 quando la capacità è 12 imposta solo un limite inferiore alla domanda reale in quel giorno. In altre parole, abbiamo bisogno di un metodo di regressione che "capisca" che 12 articoli venduti significano "12 o più articoli richiesti". La capacità finita elimina veramente le informazioni: un modello che utilizza le vendite con capacità limitata come input, anche se lo fa correttamente, sarà sempre meno preciso di un modello che utilizza la domanda non vincolata.
Nella valutazione del modello, si può spiegare la capacità finita in modo esplicito: le vendite attese sotto una data capacità finita possono essere calcolate dalla distribuzione di probabilità censurata. Ancora una volta, ricordate che le vendite attese in condizioni di vincoli di capacità non sono solo il valore più piccolo tra "la previsione della domanda non vincolata" e "la capacità", ma deve essere considerata la distribuzione di probabilità vincolata completa. Si termina quindi con un confronto come il seguente:
| Previsione della domanda media senza censure | Previsione di vendita censurata media | Mean actual sales |
| 17.84 | 14.35 | 14.66 |
In questo caso, si confermerebbe che le vendite effettive (dopo i vincoli di capacità) corrispondono bene alle aspettative.
Probabilità di riscontro della capacità prevista e frequenza di riscontro effettivo della capacità
Sebbene il confronto delle vendite previste in condizioni di vincoli di capacità con le vendite effettive aiuti a stabilire la distorsione (o la mancanza di distorsione) della previsione e sia un buon primo passo per stabilirne la qualità, spesso si incontra un certo scetticismo nei seguenti ambiti: "Riconosciamo che la previsione è complessivamente imparziale, ma temiamo che sia una previsione eccessiva e insufficiente in un modo sfortunato che porta sia a più sprechi che a più esaurimento delle scorte del necessario".
In altre parole, gli stakeholder che effettuano le previsioni non sono interessati solo all'assenza di pregiudizi globali, ma anche all'assenza di pregiudizi in ogni possibile situazione di domanda. Non vogliono sottostimare i giorni di super-vendita e controbilanciarli sovrastimando i giorni di bassa vendita. In particolare, quando la capacità è colpita, le parti interessate vogliono essere sicure di colpirla solo leggermente (solo pochi clienti se ne vanno con la loro domanda insoddisfatta); Quando c'è spreco, non dovrebbero esserci quantità enormi.
Per affrontare questa paura legittima (puoi facilmente immaginare previsioni terribili che sono globalmente imparziali e ti lasciano con un sacco di sprechi e clienti insoddisfatti), propongo di separare i dati in base alla probabilità di successo della capacità prevista. Cioè, data una previsione e un certo livello di scorte che è stato installato quel giorno, si calcola la probabilità prevista che le scorte siano esaurite, la probabilità di successo della capacità prevista. Tale probabilità di raggiungimento della capacità è vicina a 0 quando il livello delle scorte è impostato su un valore elevato rispetto alla previsione (ad esempio, quando il livello delle scorte è impostato al quantile 0,99 della distribuzione della domanda, siamo quindi certi del 99% di non raggiungere il livello di capacità). La probabilità di hit della capacità è vicina a 1 quando il livello delle scorte è piccolo, ad esempio quando è fissato al quantile 0,01- della distribuzione della domanda.
Per ogni previsione, abbiamo quindi una probabilità prevista di raggiungere la capacità (ad esempio, 0,42) e un hit di capacità effettiva (hit o no-hit). Tale evento singolo hit / no-hit è meramente aneddotico: la semplice esistenza di alcune coppie "improbabili" "probabilità di hit della capacità prevista = 0,05, ma la capacità è stata effettivamente colpita" non significa che la probabilità prevista sia fuorviante. Solo quando si dispone di una raccolta di molte previsioni probabilistiche e di eventi hit / no-hit associati, le probabilità previste possono essere verificate rigorosamente. A tale scopo, si raccolgono molte coppie di probabilità di raggiungimento della capacità (numeri a virgola mobile compresi tra 0 e 1) e di riscontri di capacità (risultati discreti, 1 per "viene raggiunto" e 0 per "non viene raggiunto"). Raccoglieteli in bucket di hit di capacità prevista di circa 0, di circa 0,10, di circa 0,20, ecc. Per ogni bucket, si calcola quindi la media del tasso di successo della capacità previsto e di quello effettivo. Quando si prevede che si verifichi un calo della capacità nello 0,10 dei casi, ci aspettiamo che in circa il 10% di questi casi la capacità venga effettivamente colpita.
Chiamiamo le probabilità previste "calibrate" quando possiamo fidarci di esse, nel senso che nel 70% di questi casi si verifica un hit di capacità previsto di 0,70 (per saperne di più sulla calibrazione, consultate il post del blog Calibrazione e nitidezza: i due aspetti indipendenti della qualità delle previsioni). Una previsione calibrata consente di prendere decisioni strategiche di rifornimento: imposta il livello delle scorte in modo tale da aspettarti di esaurire le scorte nello 0,023 dei giorni e di esaurire davvero le scorte nel 2,3% dei giorni. Questa è la gestione del rischio: si quantifica il rischio in modo calibrato, si assumono consapevolmente quei rischi che vale la pena correre.
Nella figura seguente, i cerchi neri mostrano gli eventi di hit della capacità individuale: la capacità è stata raggiunta (nella parte superiore della figura) o meno (nella parte inferiore della figura). Quando raggruppiamo tutte le previsioni, il tasso medio di successo della capacità previsto di 0,82 corrisponde alla frequenza misurata (cerchio verde). Quando segreghiamo in base alla probabilità di hit della capacità vicina a 0, a 0,1, a 0,2, ecc., vediamo che la previsione di hit della capacità è calibrata: i cerchi blu sono vicini alla diagonale.
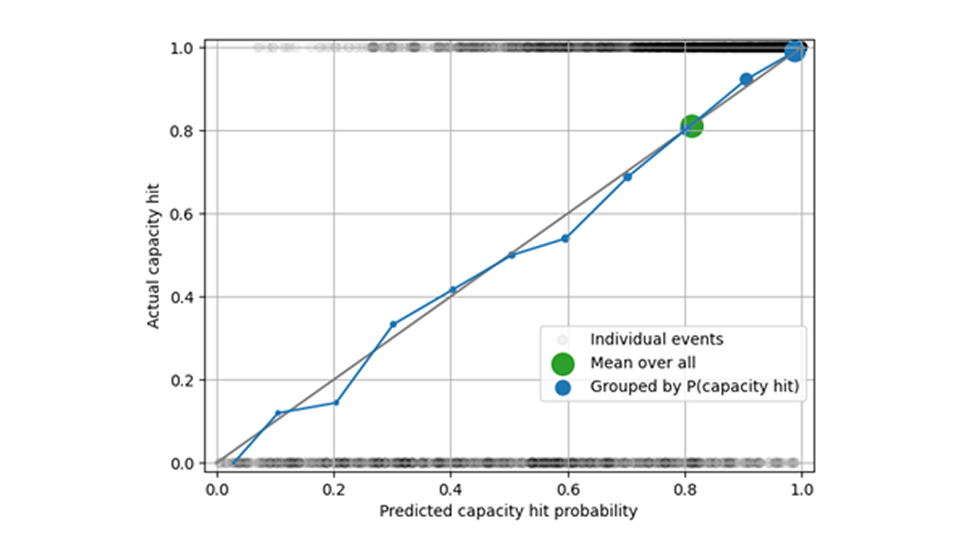
La valutazione delle probabilità e delle frequenze di hit della capacità prevista rispetto a quella effettiva non è sufficiente per garantire una buona previsione: quando si accumulano 1.000 articoli, non vi è alcuna differenza nel comportamento dei hit di capacità tra una previsione di 5, 10 o 100 – in tutti i casi, l'evento finisce nello stesso bucket "la capacità non sarà certamente raggiunta". Pertanto, un'analisi delle distorsioni tra le vendite previste dovrebbe integrare l'analisi del tasso di successo della capacità per verificare che la previsione sia imparziale sia per i vincoli di capacità che per le velocità.
In generale, il raggruppamento in base alla probabilità di successo della capacità prevista o alle vendite previste segue la regola "sii lungimirante: valuta ciò che prevedi, invece di guardare indietro" per evitare il bias del senno di poi descritto nel post del blog Non avresti dovuto sempre saperlo meglio.
Conclusione: la gestione del rischio necessita di strumenti probabilistici
Le previsioni puntuali, che producono un singolo numero come previsione, non sono adatte a gestire questioni probabilistiche strategiche come quale livello di stock può assicurare un tasso di esaurimento delle scorte inferiore all'1%. Quando si pone una domanda probabilistica – e tutte le domande sul rischio sono probabilistiche – sono necessari strumenti probabilistici per rispondere. Dovrai insegnare al tuo manager almeno una comprensione di base del "valore delle aspettative", della "censura" e della "distribuzione".
Ogni volta che la capacità ha un impatto sul mondo reale (e quasi sempre lo ha), dobbiamo prendere sul serio i limiti di capacità. Non dovremmo cercare di capire gli eventi con il senno di poi ("la capacità è stata colpita quel giorno, qual è stata la causa esatta?") ma dovremmo guardare avanti e valutare la calibrazione delle previsioni separandole in base alle vendite previste e alla probabilità di successo della capacità prevista.
Tutti gli esempi in questo post del blog sono stati costruiti in un ambiente simile a una sandbox, assumendo una previsione della domanda perfetta che produce una distribuzione ben gestita. Ti ho protetto da tutti i problemi più complessi che di solito incontreresti in contesti reali. Eppure, anche in questo semplice scenario, vediamo come la nostra intuizione sia facilmente ingannata. Pertanto, è importante non solo seguire la prima idea che si presenta su come risolvere un problema di valutazione ("raggruppiamo solo per capacità-stata-stata-colpita contro capacità-non-stata-colpita"), ma adottare una prospettiva scettica e prima simulare ciò che il metodo farebbe in un contesto ideale.
