Accelera le decisioni informate con l'AI progettata per la supply chain
Basate su decenni di innovazione nella catena di fornitura ed esperienza nell'AI, le nostre soluzioni di AI predittiva, generativa e agentica trasformano i dati grezzi in previsioni e indicazioni che aiutano i tuoi team a orientarsi in questa complessità.
Demistificazione dell'AI per i responsabili della catena di fornitura
I vantaggi dell'intelligenza artificiale per la gestione delle supply chain sono evidenti, ma l'implementazione non è sempre così diretta. Scopri perché (e come) la tua azienda dovrebbe dare priorità alle soluzioni di AI ora.
Riorganizzazione per l'AI: come i leader della supply chain devono adattarsi
Il 90% dei decisori in ambito supply chain sta attualmente eseguendo una riorganizzazione o lo farà nei prossimi 12 mesi. Molti stanno preparando i loro team a gestire catene di fornitura supportate dall'AI, ma come dovrebbero adattarsi e riorganizzarsi per un futuro incentrato sull'AI?
DHL risparmia il 7% sui costi di trasporto grazie a una migliore ottimizzazione dei veicoli e delle fermate con Blue Yonder Network Design
Carlsberg Group
Carlsberg racconta del modo in cui l'azienda sta completando il processo di digitalizzazione utilizzando la soluzione di Blue Yonder per la gestione dei trasporti, la strategia aziendale "Zero & Beyond" e altro ancora.
Walgreens
La gestione degli ordini basata sull'intelligenza artificiale di Blue Yonder supporta Walgreen nel soddisfare gli ordini dei clienti in 30 minuti.
In che modo la pianificazione basata sull'intelligenza artificiale migliorerà le prestazioni della supply chain
L'estrema volatilità, la carenza di scorte e il sovraccarico di dati sono tutte sfide che le aziende devono affrontare quando si tratta di pianificare la catena di fornitura. Le capacità di pianificazione potenziate dall'AI possono affrontare queste sfide migliorando il processo decisionale, l'agilità e la collaborazione tra le funzioni della supply chain.
2026 Supply Chain Compass: How Supply Chain leaders are navigating complexity
The Supply Chain Compass 2026 report surveys nearly 700 supply chain leaders, exploring how they are navigating a rapidly evolving landscape shaped by AI, disruption, and rising expectations. While nearly half express strong optimism about the future, the report reveals that this confidence is driven by greater visibility, stronger technology adoption, and more integrated, data-driven supply chain strategies.
Oltre i silos: evoluzione verso una catena di fornitura aziendale
Incisiv esplora la trasformazione in corso nelle moderne catene di fornitura, descrivendo in dettaglio il passaggio da processi frammentati e soluzioni puntuali a piattaforme più agili e flussi di lavoro collaborativi. Questa evoluzione risolve problemi sistemici come la mancanza di agilità e la comunicazione disconnessa, migliorando la reattività, la sostenibilità e la redditività della catena di fornitura.
L'errore percentuale assoluto medio (MAPE) ha svolto il suo dovere e ora dovrebbe andare in pensione
Blog
L'errore percentuale assoluto medio (MAPE) ha svolto il suo dovere e ora dovrebbe andare in pensione
L'errore percentuale assoluto medio (MAPE) ha svolto il suo dovere e ora dovrebbe andare in pensione
Malte Tichy, 4 minuti di lettura
Secondo Gartner (2018 Gartner Sales & Operations Planning Success Survey), la metrica di valutazione più popolare per le previsioni nella pianificazione delle vendite e delle operazioni è l'errore percentuale assoluto medio (MAPE). Questo deve cambiare. Le previsioni moderne riguardano piccole quantità a livello disaggregato come prodotto-ubicazione-giorno. Per tali previsioni granulari, i valori MAPE sono estremamente difficili da giudicare e quindi si qualificano come utili indicatori di qualità delle previsioni. MAPE inganna anche profondamente gli utenti sia esagerando alcuni problemi che mascherandone altri, spingendoli a scegliere previsioni con distorsioni sistematiche. Le situazioni in cui il MAPE è adatto diventano sempre più rare. Questa non è una teoria secca: simuliamo un supermercato che si basa su un valore di previsione ottimizzato per il MAPE immesso nel rifornimento. Le scorte insufficienti e eccessive nei venditori veloci e lenti spingono rapidamente il negozio fuori dal mercato.
Quando gli errori assoluti e relativi si contraddicono, di chi dovremmo fidarci?
Avevi previsto una domanda di 7,2 mele e 9 sono state vendute. Avevi previsto 91,8 bottiglie d'acqua e 108 sono state vendute. Avevi previsto 1,9 scatolette di tonno e una è stata venduta. Come giudichi questi errori di previsione? Un approccio semplice consiste nel calcolare la deviazione assoluta della previsione rispetto a quella effettiva e dividerla per quella effettiva, cioè l'errore assoluto relativo, possibilmente come valore percentuale (errore percentuale assoluto, APE). Questo sembra molto più complicato di quanto non sia: inventare l'APE come primo colpo per la "valutazione della qualità delle previsioni" è abbastanza tipico. Per i tre esempi, si ottengono APE apparentemente moderati del 20% (=|7.2-9|/7.2), modesto 15% (=|91.8-108|/108) e allarmante 90% (=|1.9-1|/1), rispettivamente. Il MAPE, errore percentuale assoluto medio, è la media aritmetica di queste tre percentuali, e ammonta al 41,67%. Queste percentuali di errore trasmettono che la previsione sul tonno è peggiore di quella sulle mele e la previsione sulle bottiglie supera le altre. Ma questo riflette davvero la qualità delle previsioni? Guardate di nuovo all'inizio di questa sezione: la grande differenza assoluta tra le bottiglie d'acqua previste e quelle effettive è preoccupante e il suo piccolo errore relativo non può davvero rassicurarvi. D'altra parte, l'errore del 90% sul tonno potrebbe essere dovuto a una (sfortuna) sorte: si tratta di un solo articolo. Dovresti mantenere il tuo intuito tranquillo e affidarti ciecamente agli APE? Di conseguenza, dovresti rivedere la previsione del tonno e lasciare la previsione dell'acqua così com'è? Se viene emessa un'altra previsione, con un MAPE complessivo di solo il 30%, la nuova previsione è necessariamente migliore?
Naturalmente, in nessuna circostanza vi chiederei mai seriamente di ignorare il vostro giudizio umano! Questo spiacevole paradosso è risolto di seguito: il MAPE non è adatto per le moderne previsioni probabilistiche a livello granulare (cioè sul giorno di localizzazione del prodotto, in cui possono verificarsi numeri "piccoli" o addirittura "0"), a causa di diversi problemi intollerabili e irrisolvibili. Il MAPE di una previsione non ci dice quanto sia buona quella previsione, ma quanto stranamente si comporti l'APE.
Ignorare consapevolmente la scala: quando gli errori percentuali possono avere senso
Prima di addentrarci nelle previsioni granulari nel settore della vendita al dettaglio (a livello di prodotto-posizione-giorno), supponiamo di prevedere una quantità molto più ampia: il prodotto interno lordo (PIL) annuale dei paesi, misurato in dollari USA. Tale previsione potrebbe essere utilizzata per definire politiche per interi paesi, e queste politiche dovrebbero essere ugualmente applicabili a paesi di diverse dimensioni. Pertanto, è giusto ponderare ogni paese allo stesso modo in questo caso d'uso: un errore del 5% sul PIL degli Stati Uniti (circa 25 trilioni di dollari) danneggia tanto quanto un errore del 5% sul PIL di Tuvalu (circa 66 milioni di dollari, 380.000 volte più piccolo del PIL degli Stati Uniti). Qui, l'errore percentuale assoluto (APE) ha senso: il PIL effettivo non è mai vicino a 0 (il che causerebbe un terribile mal di testa quando lo si divide, ne parlerò più avanti), e l'obiettivo della previsione non è quello di ottenere il PIL complessivo del pianeta giusto, ma di essere il più vicino possibile per ogni singolo paese, su scale che vanno da milioni a trilioni. Minimizzando l'errore assoluto totale del modello (es. in dollari USA, non in percentuale) mette sotto i riflettori le economie più grandi e ignora quelle piccole. Non pesa ogni paese allo stesso modo, ma in base al suo potere economico. Un modello con un bel errore del 3% sul PIL degli Stati Uniti e un inaccettabile errore del 200% sul PIL di Tuvalu sembrerebbe essere "migliore" di un modello con un errore del 4% sul PIL degli Stati Uniti e del 10% sul PIL di Tuvalu in termini assoluti di dollari USA. Il MAPE, d'altra parte, punta verso l'utilizzo di quest'ultima previsione, che sacrifica molto dell'accuratezza assoluta del PIL degli Stati Uniti (1% di 25 trilioni di dollari) per un modesto miglioramento assoluto dell'accuratezza di Tuvalu (190% di 66 milioni di dollari). Il PIL degli Stati Uniti è molto più grande di quello di Tuvalu, ma si deciderebbe consapevolmente, e per buone ragioni, di trattarli allo stesso modo. Sia gli Stati Uniti che Tuvalu possono essere considerati "grandi", nel senso che non ci si può aspettare che le fluttuazioni statistiche o la "sfortuna" siano responsabili dell'errore di previsione, ovvero le deviazioni saranno in genere statisticamente significative e punteranno verso un potenziale di miglioramento del modello.
In sintesi, ogni volta che le singole istanze di una previsione di valori diversi devono essere trattate in modo paritario, cioè ogni volta che ci va bene confrontare mele enormi con minuscole arance, il MAPE può avere senso. Ma la parità di trattamento è sempre equa?
Navigazione stabile in tutte le condizioni
Preparati a tutto con la newsletter di The Supply Chain Compass. Iscriviti oggi stesso per ricevere le tendenze globali e gli approfondimenti del settore, forniti mensilmente.
Tratta tutti allo stesso modo: suona bene in generale, ma non nella valutazione probabilistica delle previsioni
Torniamo al nostro precedente esempio nel settore alimentare e parliamo di mele, scatolette di tonno e bottiglie. In questo caso, confrontare gli APE ha poco senso, per due motivi.
Per definizione, un venditore lento vende meno spesso di un venditore veloce. L'impatto commerciale di una previsione di vendita lenta inaffidabile è, quindi, molto meno grave rispetto a una previsione di vendita rapida altrettanto inaffidabile. Una perdita di vendite del 5% a causa di rotture di stock in qualche slow-seller marginale è semplicemente scomoda per il venditore, mentre una perdita di vendite del 5% sull'articolo più venduto può essere piuttosto drammatica. Alla fine della giornata, i numeri assoluti contano per la tua attività. Sovrastimate del 20% la domanda totale del vostro prodotto principale negli Stati Uniti? Probabilmente hai un problema e devi avere a che fare con molte scorte invendute, il che potrebbe persino mettere a rischio l'intera attività. Sovrastimate la domanda totale dello stesso prodotto del 20% a Tuvalu? Niente contro Tuvalu (senza offesa, davvero!), ma probabilmente puoi rilassarti, dal momento che quell'errore non affonderà la tua attività. È possibile tollerare un errore relativo molto più grande in piccoli assortimenti o mercati rispetto alle categorie di pane e burro. Perché promuovere articoli marginali o gruppi di clienti alla stessa importanza dei pesci veramente grandi?
In aggiunta a questa ovvia differenza (piccolo è piccolo e grande è grande), c'è un effetto statistico sottile ma importante: la dipendenza dalla scala dell'accuratezza delle previsioni raggiungibili. Essere scontati del 10% per un prodotto che si vende 10 volte al giorno è inevitabile a volte, anche per una previsione perfetta (con l'incertezza di Poisson). Essere scontati del 10% su un prodotto che vende 10.000 volte al giorno indica chiaramente un problema. Non solo il venditore lento è meno importante dal punto di vista commerciale rispetto al venditore veloce, ma naturalmente comporta errori relativi più grandi, come discusso più dettagliatamente nei precedenti post del blog Prevedere pochi è diverso parte 1 e parte 2.
Per le previsioni della spesa di cui sopra, probabilmente sei stato sfortunato per quanto riguarda il tonno quel giorno. Le 16 bottiglie d'acqua in più sembrano meno scusabili. Pertanto, l'errore percentuale assoluto (APE) non coglie bene la qualità della previsione raggiungibile, né in termini di business (pesa equamente le cose disuguali) né in termini statistici (il suo valore raggiungibile richiede il contesto del valore previsto stesso).
Il governo del rifornimento da parte del MAPE porta a livelli di scorte catastrofici
In altre parole, il MAPE non è di per sé un buon indicatore della qualità delle previsioni: il fatto che il 20%, il 70% e il 90% siano raggiunti in tre diverse situazioni non ha un significato immediatamente interpretabile. Dato un certo valore MAPE, non si dovrebbe saltare a nessuna conclusione. Ma anche accettando che un valore MAPE dica poco o nulla sulla qualità complessiva del modello, ci si potrebbe comunque aspettare che, per una data situazione di previsione, la previsione vincente del MAPE sia la migliore. Come spiegherò ora, devi anche rinunciare a quell'aspettativa più debole.
Prendi in considerazione un supermercato che offre molti prodotti diversi, dai venditori lenti che vendono circa una volta al trimestre fino ai venditori veloci che vendono 100 volte al giorno. Il rifornimento degli articoli viene effettuato da un sistema che seleziona la previsione MAPE ottimale giornaliera e i preordini in base ad essa. In altre parole, sceglie il valore di previsione per il quale il MAPE è più basso. Come si comporterebbe quel supermercato?
Per semplificare le cose, concentrati su 5 prodotti esemplari: mele, banane, anacardi, frutti del drago e melanzane, con tassi di vendita medi giornalieri reali di 0,01, 0,1, 1, 10 e 100: la più lenta, le mele, vende circa una volta al trimestre, la più veloce, le melanzane, vende 100 volte al giorno (hai ragione se sospetti che i numeri non siano stati inventati per plausibilità nel mondo reale, ma piuttosto chiarezza e semplicità matematica). In questo esperimento mentale, conosciamo questi tassi di vendita e sono la migliore previsione possibile per ogni prodotto per costruzione. Utilizzando la distribuzione di Poisson, possiamo simulare cosa succede e qual è il valore di previsione con il miglior MAPE.
Per ogni prodotto, la tabella seguente mostra il tasso di vendita reale (che è la migliore previsione giornaliera imparziale), il suo MAPE simulato, la previsione vincente MAPE ottimizzata, il suo MAPE simulato e la sua distorsione risultante:
Prodotto
Tasso di vendita giornaliero reale, previsioni giornaliere imparziali
MAPE del tasso di vendita reale
Previsioni giornaliere vincenti MAPE
Il MAPE di MAPE vince i pronostici
Distorsione previsionale della previsione vincente di MAPE
Mele
0.01
99%
1
0.25%
+9,900%
Banane
0.1
90%
1
2.5%
+900%
Anacardi
1
23.3%
1
23.3%
0%
Frutti del drago
10
31%
9
29%
-10%
Melanzane
100
8.11%
99
8.05%
-1%
Ricordate che il vero tasso di vendita giornaliero è indiscutibilmente il miglior input possibile per il sistema di rifornimento, poiché è, per costruzione, il valore medio delle vendite previste. Cosa succede se il rifornimento utilizza invece la previsione vincente MAPE? Il supermercato fa scorta di persone che si muovono lentamente: ogni giorno, una mela, una banana e un anacardio vengono riforniti, ma le mele si vendono solo una volta ogni 100 giorni e le banane una volta ogni 10 giorni! Le mele e le banane si accumulano, gli anacardi vanno bene, mentre la domanda di frutti del drago non viene soddisfatta: in media, un cliente che voleva acquistare un frutto del drago se ne andrà senza aver completato la spesa. Per le melanzane in rapido movimento, l'errore dell'1% potrebbe essere scusabile, tuttavia, è sorprendente che la previsione "migliore" sia sempre distorta, a meno che il vero tasso di vendita non sia uguale a 1.
I numeri calcolati per la tabella sopra presuppongono un mondo perfetto in cui i previsori si divertono a lavorare con un modello con un'incertezza di Poisson minima. Per un modello più realistico in cui è presente una moderata incertezza aggiuntiva (tecnicamente parlando: sovradispersione), la situazione appare immediatamente peggiore:
Prodotto
Tasso di vendita giornaliero reale, previsioni giornaliere imparziali
MAPE del tasso di vendita reale
Previsioni giornaliere vincenti MAPE
Il MAPE di MAPE vince i pronostici
Distorsione previsionale della previsione vincente di MAPE
Mele
0.01
99%
1
0.3%
+9,900%
Banane
0.1
90%
1
3%
+900%
Anacardi
1
25%
1
25%
0%
Frutti del drago
10
73%
6
53%
-40%
Melanzane
100
49%
72
40%
-28%
Il divario tra il valore MAPE calcolato al tasso di vendita reale e il valore MAPE della previsione di vincita MAPE è aumentato notevolmente. In altre parole, l'utente potrebbe pensare che la "prova" che la previsione vincente del MAPE sia migliore dell'altra sia ancora più forte di quella precedente. La previsione MAPE ottimale è, tuttavia, più fortemente distorta rispetto alla situazione ideale: le previsioni insufficienti per i frutti del drago e le melanzane ammontano ora rispettivamente al 40% e al 28% - la conseguenza sarebbe una massiccia situazione di esaurimento delle scorte. Di seguito, vedremo perché una maggiore incertezza significa "dobbiamo giocare sul sicuro" e perché ciò significa "dobbiamo giocare piuttosto basso".
Chiaramente, un supermercato che corre con questa strategia non sopravviverà a lungo! I problemi con il MAPE vanno quindi oltre l'interpretabilità aziendale (non è opportuno rispondere alla domanda "quanto è buona la previsione?") ma può potenzialmente portare a gravi problemi operativi (scegliendo una previsione indiscutibilmente peggiore rispetto a una migliore). Scopriamo perché!
Il MAPE censura gli eventi a conteggio zero, con conseguenze catastrofiche
Quando si calcola l'APE, si incontrano seri problemi quando l'effettivo è zero, poiché dovremmo dividerlo per esso. L'APE è quindi indefinito e non entra nel calcolo del MAPE (ricorda, è la media di tutti gli APE). In altre parole, gli eventi di vendita zero vengono semplicemente rimossi dai dati. Questa rimozione dei dati, per quanto brutta possa sembrare: porta a un palese pregiudizio di sovrastima sui super-lenti (che vendono una o meno per periodo di tempo) in una previsione MAPE-ottimale: poiché gli eventi 0 vengono ignorati, la previsione ragionevole più bassa per qualsiasi prodotto, posizione e giorno è 1, anche per un prodotto che vende una volta all'anno! Poiché la previsione ottimizzata per MAPE può tranquillamente ignorare il risultato "0", giocare sul sicuro significa proporre "1" come valore di previsione più basso. Le alternative alla rimozione (ad es. assegna sempre il 100% di errore invece di rimozione) non risolvono questo problema: una previsione di 1,7 con esito 0 è chiaramente meno problematica di una previsione di 17.000 con esito 0; assegnare a questi due eventi lo stesso APE artificiale non ha senso. Ovvero, ogni volta che i dati possono plausibilmente contenere "0" come valore effettivo per qualsiasi evento, MAPE è estremamente problematico. L'ottimizzazione porterà a sovrastimazioni negli elementi che si muovono molto lentamente, come vediamo nelle prime due righe delle tabelle.
Il MAPE penalizza in modo diverso le previsioni insufficienti e eccessive, portando a stime distorte
Prevedere 1, osservare 7: l'APE è 6/7, circa. 86%. Ti sembra molto? Se è così, scambia i numeri, prevedi 7, osserva 1: il tuo APE diventa 6/1, 600%! L'APE penalizza una sovrastima di un certo fattore molto più pesantemente rispetto a una sottostima dello stesso fattore. Per le stime insufficienti, il peggior APE possibile è del 100%; Per le stime eccessive, è illimitato. Di conseguenza, ogni volta che non si è certi del risultato (non si dovrebbe mai esserlo, e ogni buon modello conosce in un certo senso la propria incertezza) giocare sul sicuro significa giocare al ribasso: evitare forti sovraprevisioni a (quasi) qualsiasi costo, mentre una massiccia sottoprevisione non vi spezzerà il collo. Pertanto, anche in condizioni di incertezza minima delle previsioni, che abbiamo assunto nella prima tabella, la previsione MAPE ottimale è una sottostima per tassi di vendita superiori a 1 (ultime due righe). Inoltre, maggiore è la variabilità dei dati di addestramento, più incerto è il modello e più la previsione MAPE ottimale sarà inferiore alla previsione: ricorda, giocare sul sicuro significa giocare basso, e più sei incerto, più vuoi essere sicuro e più bassa diventa la previsione MAPE ottimale. Questa copertura contro le sovrastime porta a una forte distorsione nelle ultime due righe della seconda tabella. Questa asimmetria è affrontata da MAPE modificati: ad esempio, l'errore percentuale può essere calcolato rispetto alla media della previsione e dell'effettivo invece che solo dell'effettivo, ma anche questi emendamenti non risolvono completamente l'asimmetria e inducono altri problemi e paradossi.
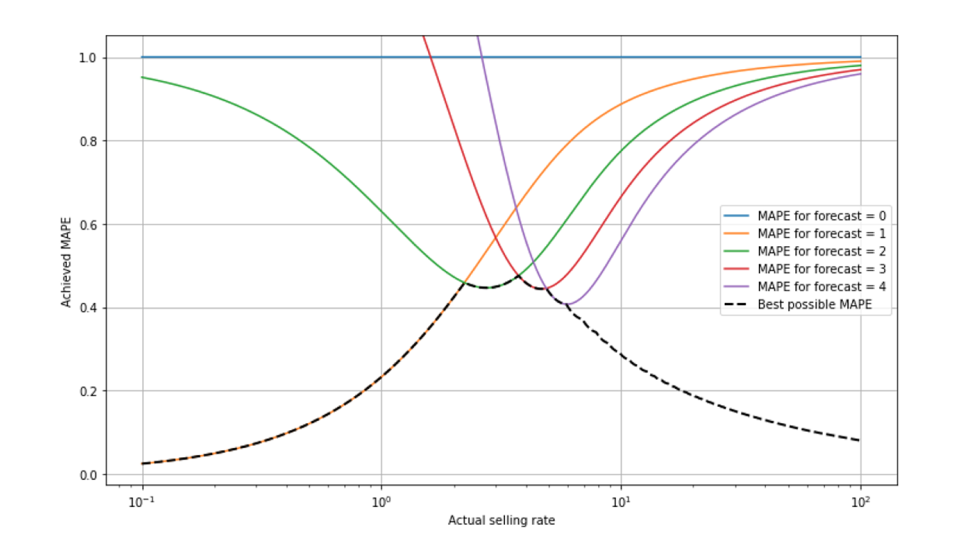
MAPE mostra un comportamento di scalabilità particolarmente complesso, lasciandoci ignoranti su quanto sia realmente buona una previsione
Certo, la mancanza di interpretabilità (il 50% di MAPE è buono o cattivo?) non è una caratteristica esclusiva del MAPE: ogni metrica dipende dalla scala e assume valori diversi per i lenti e per i veloci. Tuttavia, la scalabilità del MAPE è particolarmente intricata e complessa, a causa della combinazione dei due effetti sopra menzionati: da un lato, una previsione MAPE ottimale non produrrà mai un numero inferiore a 1 e rimuoviamo semplicemente i risultati di vendita 0. D'altra parte, gli errori relativi diminuiscono per i grandi tassi di vendita. In questo grafico, mostriamo il "monte MAPE", il miglior MAPE possibile raggiungibile in funzione del tasso di vendita.
Fai un respiro profondo e dammi la possibilità di spiegare ciò che vedi: la scala x è logaritmica, quindi possiamo osservare bene i piccoli tassi di vendita - la scala va da 0,1 a 100, da super-lento a veloce. Per piccoli tassi di vendita inferiori a circa 2, una previsione di 1 è la migliore possibile, produce il valore MAPE dato dalla linea arancione che va dalla parte inferiore sinistra (dove è sovrapposta dalla linea tratteggiata nera) all'angolo superiore destro. La previsione 2 porterebbe a un grande MAPE nei paesi a lenta rotazione (linea verde), vicino al 95% per un tasso di vendita di 0,1. La previsione 0 porta sempre a un MAPE costante del 100% (linea blu): per qualsiasi risultato che non è 0 (e questi vengono rimossi dalla valutazione), abbiamo APE=|actual-0|/actual=100%. Ad un tasso di vendita di circa 2,3, la previsione 2 diventa quella ottimale, quindi la linea tratteggiata nera, la migliore MAPE possibile, salta dalla linea arancione a quella verde. Inoltre, si alterna ogni volta che la migliore previsione passa da un valore all'altro (mostrato per la previsione 3 e 4 rispettivamente in rosso e viola).
Il miglior MAPE possibile diminuisce quando passiamo a elementi che si muovono molto lentamente (a sinistra): poiché gli eventi di vendita 0 vengono rimossi dai dati, gli eventi "sopravvissuti" sono per lo più eventi di vendita 1, e ancora di più quanto più lentamente l'articolo viene venduto. Per un tasso di vendita di 0,1, osservare 2 articoli venduti in un solo giorno è già altamente improbabile, e la previsione "1" è quindi, nella maggior parte dei casi non 0, perfetta e il MAPE raggiunto piuttosto basso. In altre parole, quando sai che "0" verrà rimosso dai dati e l'elemento è lento, allora "1" è una scommessa abbastanza sicura per il numero di vendite che si verificano. Per valori di medie dimensioni compresi tra 1 e 5, vediamo il "turn-taking" del miglior MAPE possibile. Per previsioni di grandi dimensioni pari o superiori a 10 (sul lato destro del grafico), il MAPE ottenibile diminuisce di nuovo: la distribuzione di Poisson diventa relativamente stretta nel limite dei tassi elevati (si veda il nostro precedente post sul blog su Forecasting Few is Different 1 &2).
Ho fatto del mio meglio per spiegare la forma del "monte MAPE"! Mi ci sono volute più di 300 parole in due paragrafi, ma temo che potrebbe non essere del tutto un successo: l'ha capito in modo tale da essere in grado di giudicare intuitivamente i MAPE in futuro, nel contesto dei tassi di vendita previsti? Se non credete di farlo, non preoccupatevi: questa complessità è un altro argomento modesto che, anche tra i professionisti, è improbabile che un giudizio intuitivo e corretto dei valori MAPE possa mai diffondersi.
Le previsioni MAPE ottimali sono irrilevanti per l'azienda, mettendo a rischio il potenziale valore previsto
La previsione che vince al MAPE non è la previsione imparziale che si desidera in molte applicazioni. Ma cosa significa allora "ottimizzare per MAPE"? Matematicamente, il valore che minimizza il MAPE minimizza un'espressione dall'aspetto ingombrante che non oso nemmeno scrivere in un post sul blog non rivolto agli statistici. Cosa devi sapere: questa espressione non ha un'interpretazione aziendale significativa. Qualunque cosa tu voglia ottenere con la tua previsione - garantire la disponibilità, ridurre gli sprechi, pianificare promozioni e ribassi, rifornire gli articoli, pianificare la forza lavoro... - il costo aziendale di una previsione errata nella tua applicazione non è certamente riflesso da MAPE! Idealmente, scegli una metrica di valutazione che rifletta il costo finanziario effettivo dell'"essere fuori". Non si vuole ottimizzare una funzione matematica astratta, ma massimizzare il valore aziendale.
L'alternativa: lasciare che la metrica rifletta direttamente il business
A parte situazioni come la previsione del PIL a livello nazionale e in base a forti ipotesi, il MAPE non è adatto né a indicare quanto sia buono un modello di previsione (a causa della scalabilità), né un fattore decisionale adatto a scegliere tra due modelli concorrenti (le previsioni vincenti del MAPE sono distorte). Qual è l'alternativa? In modo ottimale, la metrica utilizzata riflette direttamente il valore aziendale. L'errore assoluto medio (MAE) quantifica le situazioni in cui il costo di un articolo in eccesso è uguale al costo di un articolo mancante: un'ipotesi forte, ma sicuramente più vicina alla realtà rispetto al MAPE. Il MAE ha la stessa dimensione della previsione stessa ("numero di elementi") e quindi dipende fortemente dalla scala. Dividendo il MAE per le vendite medie, otteniamo l'errore assoluto medio relativo (RMAE), che, a causa della proprietà di scala della distribuzione di Poisson, non è nemmeno indipendente dalla scala. La dipendenza dalla scala deve quindi essere sempre affrontata in modo esplicito.
Ignorare che le stime MAPE ottimali sono distorte, tuttavia, non è un'opzione: le decisioni strategiche importanti dipendono da una valutazione delle previsioni affidabile, significativa e rilevante per l'azienda! Scegliamo il fornitore di software A, il fornitore di software B o la nostra soluzione interna? Su quali assortimenti dovremmo concentrare i nostri sforzi di miglioramento del modello? Le previsioni in questa nuova categoria sono "abbastanza buone" per rendere operativo un sistema automatizzato? La valutazione delle previsioni dovrebbe fornire prove chiare, interpretabili e che riflettano il business per rispondere a queste e a molte altre domande. MAPE non può aiutarci in questo.
Scopri come correggere l'errore assoluto medio
L'errore assoluto medio (MAE) fornisce metriche di performance incomplete? Scopri perché il MAE deve essere corretto e i passaggi fondamentali per una migliore valutazione del modello.