
















Si è parlato molto di come l'IA generativa cambierà il lavoro nella catena di approvvigionamento. Noi di Blue Yonder abbiamo voluto esaminare questi impatti attraverso uno studio di benchmarking. Nel nostro esperimento di ricerca, abbiamo esplorato la capacità dei modelli linguistici di grandi dimensioni (LLM) e se possono essere applicati efficacemente all'analisi della supply chain per affrontare i problemi reali affrontati nella gestione della supply chain.
Gli LLM, incluso ChatGPT, sono un tipo di intelligenza artificiale addestrata su enormi quantità di dati, che consente loro di apprendere i modelli, la grammatica e la semantica del linguaggio. Negli ultimi anni, gli LLM sono esplosivi in crescita e sono utilizzati in una vasta gamma di applicazioni in tutto il mondo, tra cui la creazione di contenuti, il servizio clienti e le ricerche di mercato.
I dati di IDC rivelano che si prevede che i settori del software e dei servizi informativi, bancari e della vendita al dettaglio destineranno circa 89,6 miliardi di dollari all'IA nel 2024, con l'IA generativa che rappresenterà oltre il 19% dell'investimento totale.
Questa tecnologia in rapida evoluzione offre alle aziende maggiore creatività, efficienza e capacità decisionali, che hanno il potere di rivoluzionare settori e processi. Quindi, in che modo gli LLM gestiscono attualmente le situazioni della catena di approvvigionamento?
Informazioni sullo studio di benchmark sull'intelligenza artificiale generativa di Blue Yonder
Il nostro test generativo della catena di approvvigionamento dell'intelligenza artificiale si basa vagamente sull'esperimento virale di ChatGPT chiamato Uniform Bar Examination. In questo studio, l'ultima versione di ChatGBT ha superato l'esame di avvocato con un punteggio combinato elevato di 297, avvicinandosi al 90° percentile di tutti i partecipanti al test. Superando l'asticella con un punteggio quasi del 10%, gli LLM dimostrano la capacità dell'IA generativa di comprendere e applicare i principi e le normative legali. Questo studio rivoluzionario ha scatenato una conversazione globale e ha evidenziato il potenziale trasformativo dell'intelligenza artificiale.
Blue Yonder ha deciso di fare un ulteriore passo avanti in questa conversazione studiando come i principali sistemi LLM potrebbero comportarsi negli esami del settore della supply chain. Abbiamo avuto LLM che si sono confrontati con due test di certificazione standard, il CPSM e il CSCP. Il nostro obiettivo? Per vedere se gli LLM potevano funzionare come professionisti della supply chain, comprendendo le regole di nicchia e il contesto del settore della supply chain senza formazione.
Abbiamo progettato l'esperimento per eseguire in modo programmatico ogni LLM attraverso i test pratici, senza alcun contesto intorno al test, senza accesso a Internet e senza capacità di codifica. Volevamo valutare le prestazioni degli LLM fin da subito, consentendo una valutazione coerente e imparziale.
Sia il test di certificazione CPSM che quello CSCP sono a scelta multipla. Piuttosto che fare in modo che gli LLM selezionino semplicemente una risposta, impostiamo un output per i modelli per spiegare ogni scelta che hanno selezionato. Questo approccio ci ha permesso di ottenere informazioni preziose sul processo di ragionamento di ciascun modello e di capire perché le risposte erano sbagliate o giuste, aiutandoci a valutare le capacità di ciascun modello.
Dopo il rilascio delle versioni aggiornate degli LLM, abbiamo eseguito nuovamente il test quest'estate per raccogliere nuovi risultati di benchmark.
Quindi, gli LLM possono superare gli esami della catena di approvvigionamento?
Sorprendentemente, gli LLM si sono comportati sorprendentemente bene negli esami della catena di approvvigionamento senza alcuna formazione. Per prima cosa abbiamo esaminato le prestazioni pronte all'uso degli LLM, senza contesto, quindi abbiamo aggiunto alcuni vantaggi.
Fase 1: Nessun contesto, nessun accesso a Internet, nessuna capacità di codifica
Mentre la maggior parte dei modelli ha ottenuto un solido voto di superamento senza contesto, Claude 3.5 Sonnet si è distinto, garantendo un'impressionante precisione del 79,71% nel test di certificazione CPSM. Nell'esame CSCP, i modelli o1-Preview e GPT 4o di OpenAI hanno superato Claude Opus, con una precisione del 48,30% rispetto al 45,7% di quest'ultimo.
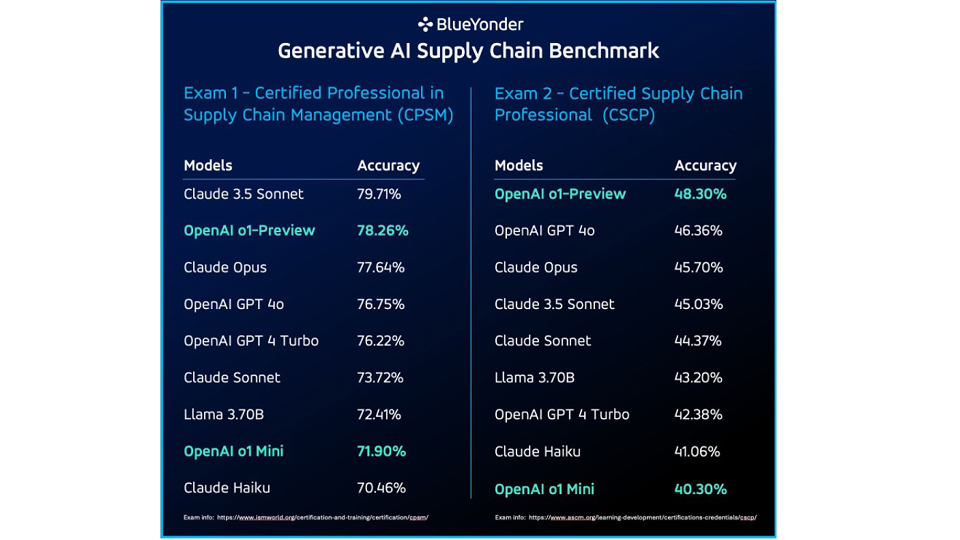
Sebbene gli LLM abbiano ottenuto buoni risultati in alcune aree, hanno anche mostrato dei limiti, in particolare quando si sono trovati di fronte a domande relative alla matematica o a domande profondamente specifiche del dominio.
Esaminando solo i problemi matematici in ogni esame di certificazione, OpenAI o1 Mini ha mostrato un miglioramento significativo dell'accuratezza per i modelli OpenAI, superando i modelli Claude testati.

Questi risultati sono stati generati in base all'assenza di contesto, all'accesso a Internet e all'impossibilità di codificare. Successivamente, abbiamo esplorato cosa accadrebbe se iniziassimo a fornire maggiore assistenza agli LLM.
Fase 2: Aggiunta dell'accesso a Internet
Nella fase successiva di test, abbiamo dato ai programmi LLM l'accesso a Internet, consentendo loro di effettuare ricerche utilizzando you.com. Con questa capacità aggiuntiva, OpenAI GPT 4 Turbo ha ottenuto l'avanzamento più significativo, dal 42,38% al 48,34%, nel test CSCP.
Esaminando le domande che inizialmente non erano state collocate nel primo test senza contesto, il modello Claude Sonnet ha ottenuto un punteggio di accuratezza di circa il 53,84% per le domande CPSM e del 20% per le domande CSCP.
Se da un lato l'accesso a Internet ha permesso ai modelli di cercare informazioni in modo indipendente, dall'altro ha introdotto il potenziale di imprecisioni dovute a fonti di informazione online inaffidabili.
Fase 3: Fornire un contesto con RAG
Per il test successivo, abbiamo utilizzato un modello RAG (retrieval augmented generation), fornendo agli LLM i materiali di studio dei test. Utilizzando il RAG, l'LLMS ha superato sia i test senza contesto che quelli di accesso a Internet aperto su domande non matematiche, ottenendo i punteggi di accuratezza più elevati per entrambi i test.
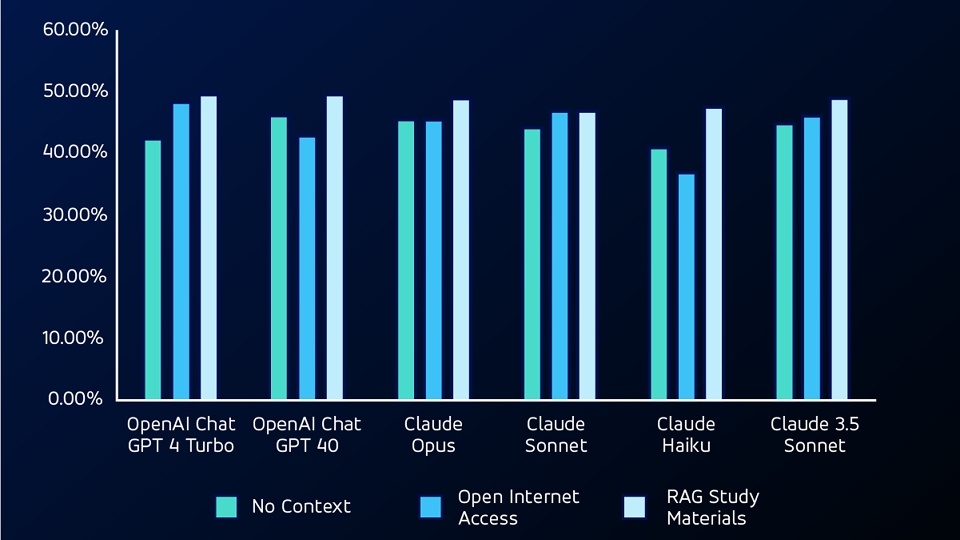
Fase 4: Aggiunta di capacità di codifica
Infine, per il test successivo, abbiamo dato ai modelli la possibilità di scrivere ed eseguire il proprio codice utilizzando i framework Code Interpreter e Open Interpreter.
Utilizzando questi framework, gli LLM potevano scrivere codice per aiutare a risolvere le domande matematiche negli esami, con cui avevano difficoltà nella prima iterazione del test. Con le capacità di codifica, gli LLM hanno superato il test senza contesto di una media di circa il 28% in termini di accuratezza in tutti i modelli per le domande matematiche.
Gli LLM sono utili per risolvere i problemi della catena di approvvigionamento?
Nel complesso, i sistemi LLM hanno superato gli esami standard del settore per la catena di approvvigionamento. Questa performance rappresenta una possibilità molto interessante per l'integrazione degli LLM nella gestione della supply chain. Tuttavia, i modelli non sono ancora perfetti. Hanno lottato sia con problemi matematici che con la logica specifica della catena di approvvigionamento.
Con l'aggiunta della capacità di scrivere codice, gli LLM sono stati in grado di superare molti dei problemi matematici, ma avevano comunque bisogno di un contesto molto specifico della catena di approvvigionamento per risolvere alcune delle domande più complesse all'interno degli esami.
Ciò che il nostro studio ha rivelato è che l'intelligenza artificiale generativa può essere estremamente utile per risolvere i problemi della catena di approvvigionamento, con gli strumenti e la formazione giusti.
Fortunatamente, questo è ciò in cui Blue Yonder eccelle. Ci impegniamo a sfruttare la potenza dell'intelligenza artificiale generativa per creare soluzioni pratiche e innovative per le sfide della supply chain. Il nostro nuovo AI Innovation Studio è un hub per lo sviluppo di queste soluzioni, colmando il divario tra le complesse tecnologie di intelligenza artificiale e le applicazioni del mondo reale.
Il nostro obiettivo è creare agenti intelligenti su misura per ruoli specifici all'interno della catena di fornitura, garantendo che questi agenti siano attrezzati per risolvere i problemi e le sfide reali e autentiche affrontate in questo momento. Scopri di più sull'intelligenza artificiale e l'apprendimento automatico su Blue Yonder o contattaci per iniziare una conversazione individuale.
