Che cos'è una buona previsione?
Le previsioni sono come gli amici: la fiducia è il fattore più importante (non vuoi mai che i tuoi amici ti mentiscano), ma tra i tuoi amici fidati, preferisci incontrare quelli che ti raccontano le storie più interessanti.
Cosa intendo con questa metafora? Vogliamo che le previsioni siano "buone", "accurate" e "precise". Ma cosa intendiamo con questo? Affiniamo i nostri pensieri per articolare e visualizzare meglio ciò che vogliamo da una previsione. Esistono due modi indipendenti in cui è possibile misurare la qualità delle previsioni ed è necessario considerarli entrambi, la calibrazione e la nitidezza, per ottenere una comprensione soddisfacente delle prestazioni della previsione.
Calibrazione delle previsioni
Per semplicità, iniziamo con la classificazione binaria: il risultato previsto può assumere solo due valori, "vero o falso", "0 o 1" o simili.
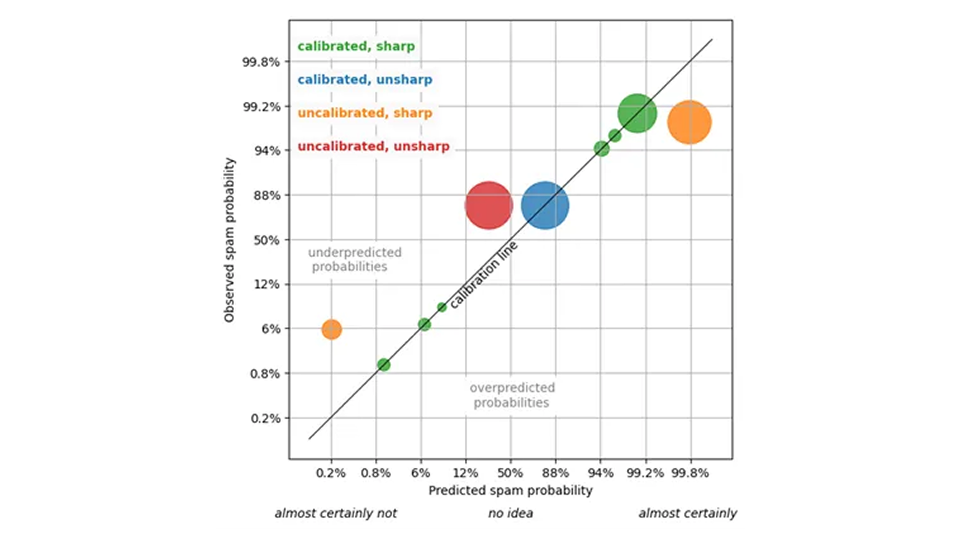
Per essere più concreti, consideriamo le e-mail e se verranno contrassegnate come spam dall'utente della casella di posta. Un sistema predittivo produce, per ogni email, una percentuale di probabilità che questa email venga considerata spam dall'utente (che consideriamo la verità di base). Al di sopra di una certa soglia, diciamo il 95%, l'email finisce poi nella cartella spam.
Per valutare questo sistema, si può, in primo luogo, verificare la calibrazione della previsione: per quelle e-mail a cui viene assegnata una probabilità di spam dell'80%, la frazione di vero spam dovrebbe essere intorno all'80% (o almeno non differire in modo statisticamente significativo). Per quelle e-mail a cui è stata assegnata una probabilità di spam del 5%, la frazione di vero spam dovrebbe essere di circa il 5% e così via. Se questo è il caso, possiamo fidarci della previsione: una presunta probabilità del 5% è in realtà una probabilità del 5%.
Una previsione calibrata ci permette di prendere decisioni strategiche: ad esempio, possiamo impostare la soglia della cartella spam in modo appropriato e possiamo stimare in anticipo il numero di falsi positivi / falsi negativi (è inevitabile che un po' di spam arrivi nella casella di posta e che alcune e-mail importanti finiscano nella cartella spam).
Nitidezza delle previsioni
La calibrazione è tutto ciò che serve per prevedere la qualità? Non proprio! Immagina una previsione che assegna la probabilità complessiva di spam – 85% – a ogni email. Questa previsione è ben calibrata, dal momento che l'85% di tutte le e-mail sono spam o comunque dannose. Puoi fidarti di quella previsione; non ti sta mentendo, ma è abbastanza inutile: non puoi prendere alcuna decisione utile sulla banale affermazione ripetuta "la probabilità che questa email sia spam è dell'85%".
Una previsione utile è quella che assegna probabilità molto diverse a e-mail diverse: 0,1% di probabilità di spam per l'e-mail del tuo capo, 99,9% per annunci farmaceutici dubbi , e che rimane calibrata. Questa proprietà di utilità è chiamata nitidezza dagli statistici, in quanto si riferisce all'ampiezza della distribuzione prevista dei risultati, data una previsione: più ristretta, più nitida.
Una previsione non individualizzata che produce sempre la probabilità di spam dell'85% è massimamente non nitida. La massima nitidezza significa che il filtro antispam assegna solo lo 0% o il 100% di probabilità di spam a ogni e-mail. Questo massimo grado di nitidezza – il determinismo – è auspicabile, ma non è realistico: tale previsione (molto probabilmente) non sarà calibrata, e alcune e-mail contrassegnate con lo 0% di probabilità di spam si riveleranno spam, alcune e-mail contrassegnate con il 100% di probabilità di spam risulteranno essere del tuo partner.
Qual è allora la migliore previsione? Non vogliamo rinunciare alla fiducia, quindi la previsione deve rimanere calibrata, ma all'interno delle previsioni calibrate, vogliamo quella più nitida. Questo è il paradigma della previsione probabilistica, che è stato formulato da Gneiting, Balabdaoui e Raftery nel 2007 (J. R. Statista. Soc. B 69, Parte 2, pagg. 243-268): Massimizza la nitidezza, ma non compromette la calibrazione. Fai l'affermazione più forte possibile, a condizione che rimanga vera. Come con i nostri amici, raccontami la storia più interessante, ma non mentirmi. Per un filtro antispam, la previsione più precisa assegna valori come l'1% per le email che chiaramente non sono spam, il 99% per le email che sono chiaramente spam e un valore intermedio per i casi difficili da decidere (che non dovrebbero essere troppi).